This article discusses how we design audio applications in terms of the processing graph. Ever asked yourself any of the following questions?
How do I:
- handle multiple tracks?
- achieve side-chaining?
- keep sample accurate timing?
- implement time-stretching?
- allow multi-threading?
So its easy to see that a lot of different factors come into play when designing a real-time safe, multi-track, side-chain-capable, sample-accurate, time-stretching and multi-threaded audio engine.
The Question
The first thing to concider is should we start processing at the start of a “track” or “chain” of signal-processors, and work towards the end, or start at the end? In the following, the arrows indicate the direction of a pointer to which is the next node to process().
Input to output
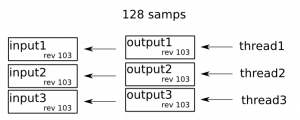
There’s actually a few reasons: say we start with the “input” audio buffer, and we want to produce 128 samples at the output. A pretty normal use case, illustrated by the image below. This use case is so simple, both push and pull work.

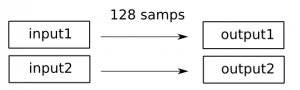
Multiple tracks
For the next use case, we’re going to add another “tracks”, which has a totally different chain of processors attached. Illustrated by the diagram below, and again a push or pull will work.
Side chaining
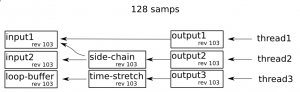
So now lets include a side-chain: where one track needs audio from the other track. This is a common use-case, particularly in the production of modern electronic music, and is something that needs to be handled appropriatly. See the diagram below;
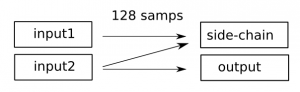
Pull model, side-chaining
When using a push model, we now have a problem. How can the graph know it has to process input2 before side-chain? It can’t. Not easily anyway. But what if we use a pull model for this? The problem no longer-exists, as we can “pull” the input buffer to the side-chain block!
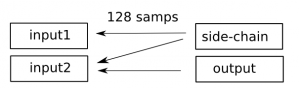
Sample accuracy and pull
So what about sample-accuracy? We need to ensure that the input2 block doesn’t process twice, so we should keep a note of what process revision its on. A _revision_is just like a git-commit in a way; it indicates what number of process() callbacks it has completed. This allows a block to check if it has already done process() for this nframes, and just return the audio, keeping in sample-accurate sync.
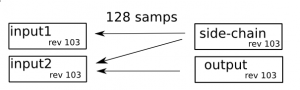
Time-Stretching
A similar problem occurs with side-chaining when we do time-stretching. The cause of the problem is that some (generally the best sounding) time-stretch algorithms do not always produce the same number of output samples as input samples.
This leads to a problem that when we “push” 128 samples trough the chain, and there is a node which does time-stretching, we are not gauranteed to have 128 samples at the output : and there’s no proper way to fix this!
Pull model to the rescue: we can call process() on the time-stretch node again, which will cause it to call its input-node, which reads more data from the looping-buffer, and the time-stretching occurs gracefully, without issues.

Multi-threading
So now we want to multi-thread an entire graph, based on the pull model. Do this: start as many threads as there are outputs: each thread starts by calling process() on one output. If the graph is entirely “seperated” or “parralel”, then the processing occurs in best-case time!
What about side-chaining and time-stretching? How does that scale, threads could do simultaneous read/write from data etc! Yes, so we protect each node with two atomics:
- bool currently_being_processed;
- atomic_int_t revision_ID;
When a thread enters a node’s process(), if currently_being_processed is true it blocks until false. Then it compares the revision_ID to the threads process() revision, and if identical, it just copies the data from the node’s buffer. Otherwise it calls sets currently_being_processed to true, and calls process().
Conclusion
This type of networked graph is difficult to use, but from the examples given it is clear that if flexible side-chaining and time-stretching, with sample accuracy and multi-threading is required, then this is probably one of the only methods that actually works, and scales well!
Notes
Checkout JACK and PD for other sources of inspiration for audio-engines.